BASIC DATAVISUALISATION PROJECT WORKFLOW
SETTING UP A DATAVISUALISATION PROJECT
This simplified illustration aims to explain the role of each service we usually encounter in a data-visualisation project : from the raw data on your desktop (CSV, XLS…) to an online interactive data-visualisation/valorisation service (a website for instance).
Note : this illustration simply lists all those services, but an online data-visualisation service could either contain all those necessary services (as a monolithic app) or be just one part of inter-operable services (as Apiviz).
illustration
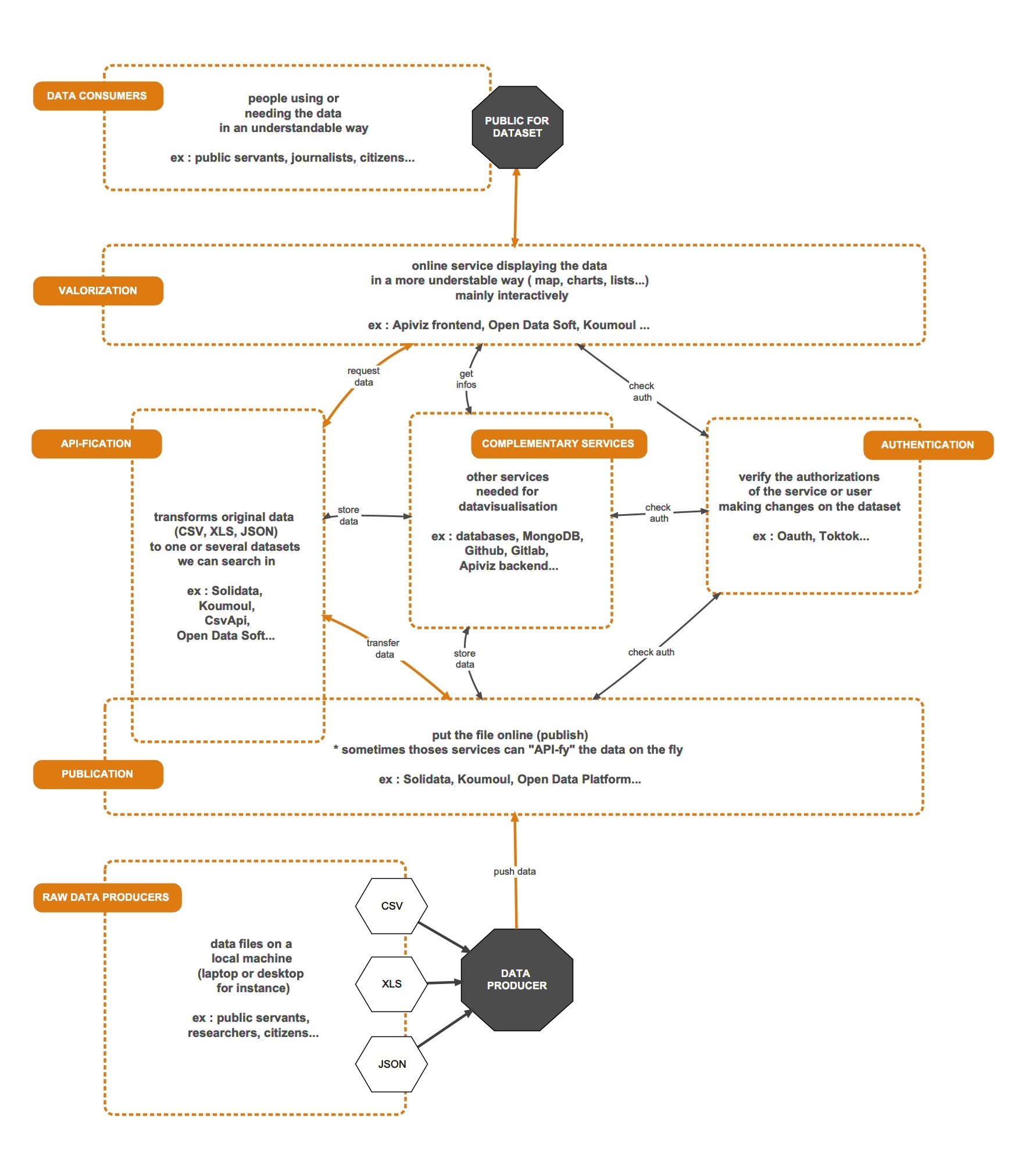
BASIC DATA WORKFLOW THROUGH SERVICES
Usually in a data-visualisation project an user owning data - aka the data producer - would like to show its original and raw data in an interactive and prettier form. The “raw data” could be a csv or excel file, or even a json.
To do interactive visualisation (show charts, diagrams, maps… corresponding to the original spreadsheet), the data must be :
uploaded online
so the data is accesible on the web and not only on the data producer’s laptop. This is the upstream part of the data workflow.
transformed as a requestable dataset
so we could make slices, requests, agregations, … as such this represents the “search engine” part of the process, and usually the transformed data must be stored somewhere on thee web (database, github repo…)
rendered / displayed
this is the data-visualisation part of the process. The search engine fetches data slices we requested, and the data slices are transformed into charts, maps, diagrams… or even downloaded downstream
other services
Optionnaly during the second part the data could be enriched from other sources (like adding geo-location to a dataset containing only adresses as text)
Under the “hood” several other services are usually necessary for all those processes to run smoothly, in particular when some users are allowed to modify the original dataset or the data-visualisation configurations. As such authentication services are often required to check the user’s rights on the datasets, whichever action is done on any part of the process.